Interpreter in Apache Zeppelin
Overview
In this section, we will explain about the role of interpreters, interpreters group and interpreter settings in Zeppelin. The concept of Zeppelin interpreter allows any language/data-processing-backend to be plugged into Zeppelin. Currently, Zeppelin supports many interpreters such as Scala ( with Apache Spark ), Python ( with Apache Spark ), Spark SQL, JDBC, Markdown, Shell and so on.
What is Zeppelin interpreter?
Zeppelin Interpreter is a plug-in which enables Zeppelin users to use a specific language/data-processing-backend. For example, to use Scala code in Zeppelin, you need %spark interpreter.
When you click the +Create button in the interpreter page, the interpreter drop-down list box will show all the available interpreters on your server.
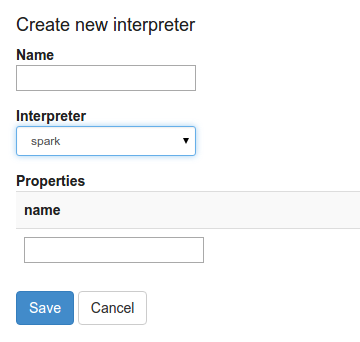
What is interpreter setting?
Zeppelin interpreter setting is the configuration of a given interpreter on Zeppelin server. For example, the properties are required for hive JDBC interpreter to connect to the Hive server.
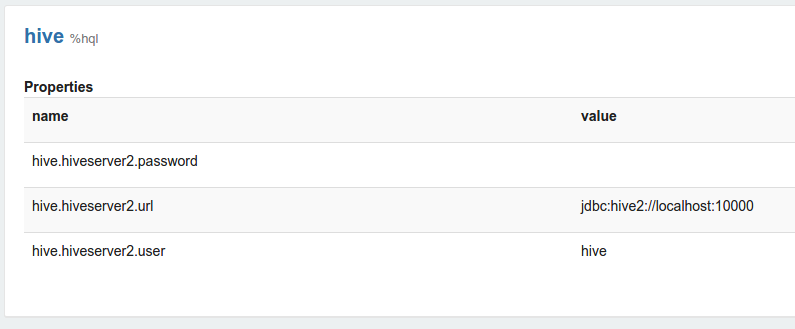
Properties are exported as environment variables when property name is consisted of upper characters, numbers and underscore ([A-Z_0-9]). Otherwise set properties as JVM property.
You may use parameters from the context of interpreter by add #{contextParameterName} in value, parameter can be of the following types: string, number, boolean.
Context parameters
| Name | Type |
|---|---|
| user | string |
| noteId | string |
| replName | string |
| className | string |
If context parameter is null then replaced by empty string.

Each notebook can be bound to multiple Interpreter Settings using setting icon on upper right corner of the notebook.
What is interpreter group?
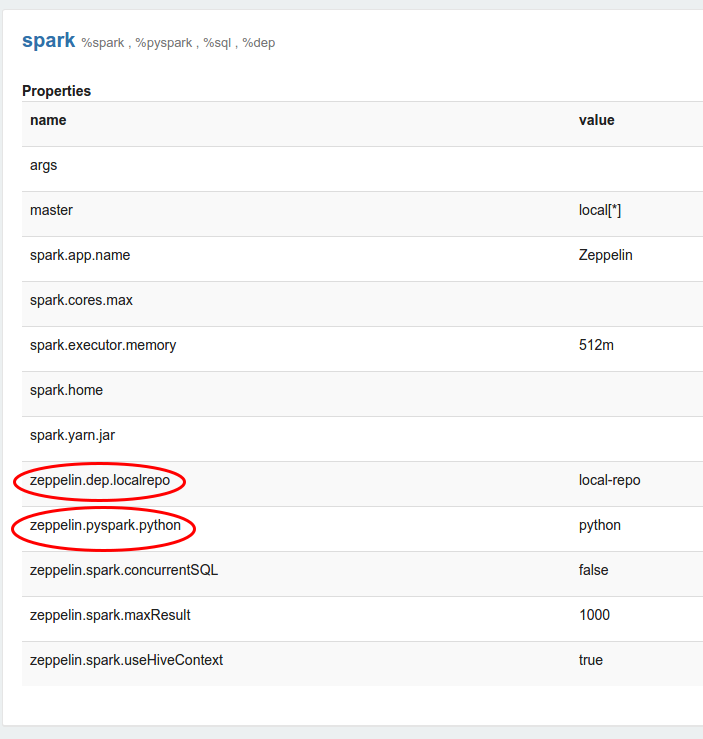
Every Interpreter is belonged to an Interpreter Group. Interpreter Group is a unit of start/stop interpreter. By default, every interpreter is belonged to a single group, but the group might contain more interpreters. For example, Spark interpreter group is including Spark support, pySpark, Spark SQL and the dependency loader.
Technically, Zeppelin interpreters from the same group are running in the same JVM. For more information about this, please checkout here.
Each interpreters is belonged to a single group and registered together. All of their properties are listed in the interpreter setting like below image.
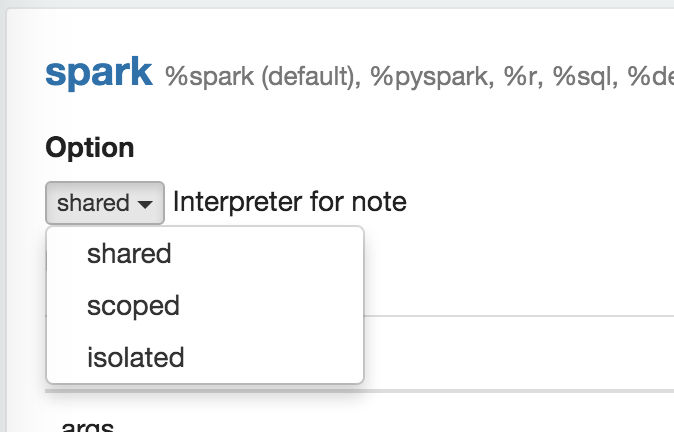
Interpreter binding mode
Each Interpreter Setting can choose one of 'shared', 'scoped', 'isolated' interpreter binding mode. In 'shared' mode, every notebook bound to the Interpreter Setting will share the single Interpreter instance. In 'scoped' mode, each notebook will create new Interpreter instance in the same interpreter process. In 'isolated' mode, each notebook will create new Interpreter process.
For more information, check Interpreter Binding Mode.
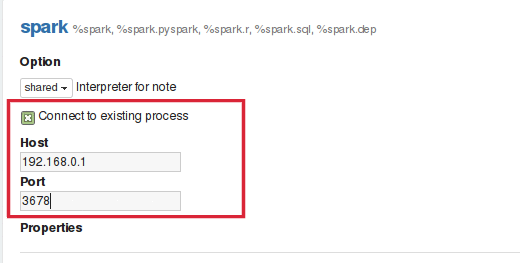
Connecting to the existing remote interpreter
Zeppelin users can start interpreter thread embedded in their service. This will provide flexibility to user to start interpreter on remote host. To start interpreter along with your service you have to create an instance of RemoteInterpreterServer and start it as follows:
RemoteInterpreterServer interpreter=new RemoteInterpreterServer(3678);
// Here, 3678 is the port on which interpreter will listen.
interpreter.start();
The above code will start interpreter thread inside your process. Once the interpreter is started you can configure zeppelin to connect to RemoteInterpreter by checking Connect to existing process checkbox and then provide Host and Port on which interpreter process is listening as shown in the image below:
Precode
Snippet of code (language of interpreter) that executes after initialization of the interpreter depends on Binding mode. To configure add parameter with class of interpreter (zeppelin.<ClassName>.precode) except JDBCInterpreter (JDBC precode).

Interpreter Lifecycle Management
Before 0.8.0, Zeppelin don't have lifecycle management on interpreter. User have to shutdown interpreters explicitly via UI. Starting from 0.8.0, Zeppelin provides a new interface
LifecycleManager to control the lifecycle of interpreters. For now, there're 2 implementations: NullLifecycleManager and TimeoutLifecycleManager which is default.
NullLifecycleManager will do nothing,
user need to control the lifecycle of interpreter by themselves as before. TimeoutLifecycleManager will shutdown interpreters after interpreter idle for a while. By default, the idle threshold is 1 hour.
User can change it via zeppelin.interpreter.lifecyclemanager.timeout.threshold. TimeoutLifecycleManager is the default lifecycle manager, user can change it via zeppelin.interpreter.lifecyclemanager.class.
Generic ConfInterpreter
Zeppelin's interpreter setting is shared by all users and notes, if you want to have different setting you have to create new interpreter, e.g. you can create spark_jar1 for running spark with dependency jar1 and spark_jar2 for running spark with dependency jar2.
This approach works, but not so convenient. ConfInterpreter can provide more fine-grained control on interpreter setting and more flexibility.
ConfInterpreter is a generic interpreter that could be used by any interpreters. The input format should be property file format.
It can be used to make custom setting for any interpreter. But it requires to run before interpreter process launched. And when interpreter process is launched is determined by interpreter mode setting.
So users needs to understand the (interpreter mode setting of Zeppelin and be aware when interpreter process is launched. E.g. If we set spark interpreter setting as isolated per note. Under this setting, each note will launch one interpreter process.
In this scenario, user need to put ConfInterpreter as the first paragraph as the below example. Otherwise the customized setting can not be applied (Actually it would report ERROR)

Interpreter Process Recovery
Before 0.8.0, shutting down Zeppelin also mean to shutdown all the running interpreter processes. Usually admin will shutdown Zeppelin server for maintenance or upgrade, but don't want to shut down the running interpreter processes.
In such cases, interpreter process recovery is necessary. Starting from 0.8.0, user can enable interpreter process recovering via setting zeppelin.recovery.storage.class as
org.apache.zeppelin.interpreter.recovery.FileSystemRecoveryStorage or other implementations if available in future, by default it is org.apache.zeppelin.interpreter.recovery.NullRecoveryStorage
which means recovery is not enabled. Enable recover means shutting down Zeppelin would not terminating interpreter process,
and when Zeppelin is restarted, it would try to reconnect to the existing running interpreter processes. If you want to kill all the interpreter processes after terminating Zeppelin even when recovery is enabled, you can run bin/stop-interpreter.sh
Credential Injection
Credentials from the credential manager can be injected into Notebooks. Credential injection works by replacing the following patterns in Notebooks with matching credentials for the Credential Manager: {user.CREDENTIAL_ENTITY} and {password.CREDENTIAL_ENTITY}. However, credential injection must be enabled per Interpreter, by adding a boolean injectCredentials setting in the Interpreters configuration. Injected passwords are removed from Notebook output to prevent accidentally leaking passwords.
Credential Injection Setting

Credential Entry Example

Credential Injection Example
val password = "{password.SOME_CREDENTIAL_ENTITY}"
val username = "{user.SOME_CREDENTIAL_ENTITY}"